


 50010702506256
50010702506256


 分类:
随笔
分类:
随笔
解释1、
栈是编译期间就分配好的内存空间,因此你的代码中必须就栈的大小有明确的定义;堆是程序运行期间动态分配的内存空间,你可以根据程序的运行情况确定要分配的堆内存的大小
解释2、
存放在栈中时要管存储顺序,保持着先进后出的原则,他是一片连续的内存域,有系统自动分配和维护。
而堆是无序的,他是一片不连续的内存域,有用户自己来控制和释放,如果用户自己不释放的话,当内存达到一定的特定值时,通过垃圾回收器(GC)来回收。
引用类型总是存放在堆中。
值类型和指针总是放在它们被声明的地方。
调用方法:系统先将一段编码(堆的首部地址)放到栈上,紧接着放置方法的参数。然后代码执行到方法时,查找栈中放该堆首部地址的所有参数,并通过堆的首部地址来控制堆。
引用类型:总是放在堆当中。
当我们使用引用类型时,实际上只是在处理该类型的指针。而非引用类型本身,使用值类型的话则是使用其本身。
解释3.
线程堆栈:简称栈 Stack
托管堆: 简称堆 Heap
使用.Net框架开发程序的时候,我们无需关心内存分配问题,因为有GC这个大管家给我们料理一切。如果我们写出如下两段代码:
code1:
public int AddFive(int pValue)
{
int result;
result = pValue + 5;
return result;
}code2:
public class MyInt
{
public int MyValue;
}
public MyInt AddFive(int pValue)
{
MyInt result = new MyInt();
result.MyValue = pValue + 5;
return result;
}问题1:你知道代码段1在执行的时候,pValue和result在内存中是如何存放,生命周期又如何?代码段2呢?
要想释疑以上问题,我们就应该对.Net下的栈(Stack)和托管堆(Heap)(简称堆)有个清楚认识,本立而道生。如果你想提高程序性能,理解栈和堆,必须的!
本文就从栈和堆,类型变量展开,对我们写的程序进行庖丁解牛。
C#程序在CLR上运行的时候,内存从逻辑上划分两大块:栈,堆。这俩基本元素组成我们C#程序的运行环境。
一,栈 vs 堆:区别?
栈通常保存着我们代码执行的步骤,如在代码段1中 AddFive()方法,int pValue变量,int result变量等等。
而堆上存放的则多是对象,数据等。
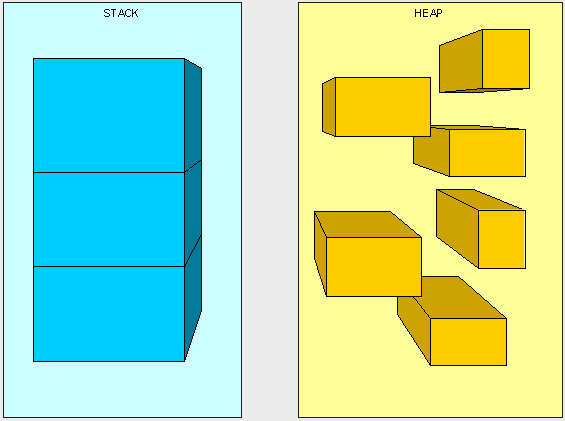
我们可以把栈想象成一个接着一个叠放在一起的盒子(越高内存地址越低)。当我们使用的时 候,每次从最顶部取走一个盒子,当一个方法(或类型)被调用完成的时候,就从栈顶取走(called a Frame,译注:调用帧),接着下一个。
栈内存无需我们管理,也不受GC管理。当栈顶元素使用完毕,立马释放。而堆则需要GC(Garbage collection:垃圾收集器)清理。
堆则不然,像是一个仓库,储存着我们使用的各种对象等信息,跟栈不同的是他们被调用完毕不会立即被清理掉。
如图1,栈与堆示意图
二,引用和值类型如何分配?
我们先看一下两个观点:
观点1,引用类型总是被分配在堆上。(正确?)
观点2,值类型和指针总是分配在被定义的地方,他们不一定被分配到栈上。
上文提及的栈(Stack),在程序运行的时候,每个线程(Thread)都会维护一个自己的专属线程堆栈。
当一个方法被调用的时候,主线程开始在所属程序集的元数据中,查找被调用方法,然后通过JIT即时编译并把结果(一般是本地CPU指令)放在栈顶。CPU通过总线从栈顶取指令,驱动程序以执行下去。
下面我们以实例来详谈。
还是我们开篇所列的代码段1:
public int AddFive(int pValue)
{
int result;
result = pValue + 5;return result;
}当AddFive方法开始执行的时候,方法参数(parameters)则在栈上分配。如图3:
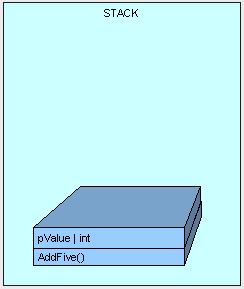
注意:方法并不在栈中存活,图示仅供参考。
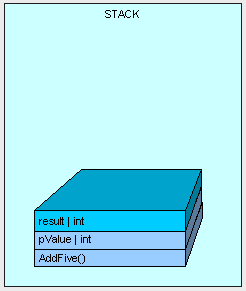
接着,指令指向AddFive方法内部,如果该方法是第一次执行,首先要进行JIT即时编译。如图4:
方法执行完毕,而且方法返回后,如图6所示:
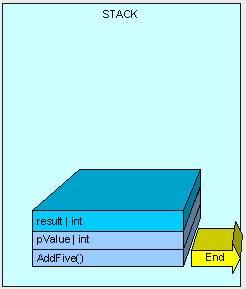
在方法执行完毕返回后,栈上的区域被清理。如图7:
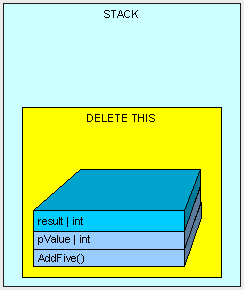
现在可以回答第一个问题了 : 很明显 pValue 与 result 都是被分配在stack上的,而且生命周期为这个函数的生命周期
以上看出,一个值类型变量,一般会分配在栈上。那观点2中所述又做何理解?“值类型和指针总是分配在被定义的地方,他们不一定被分配到栈上”。
原因就是如果一个值类型被声明在一个方法体外并且在一个引用类型中,那它就会在堆上进行分配。
还是代码段2:
public class MyInt
{
public int MyValue;
}
public MyInt AddFive(int pValue)
{
MyInt result = new MyInt();
result.MyValue = pValue + 5;
return result;
}刚开是的时候和代码段一是一样的,先找到方法,然后定义参数 pValue

接下来就不一样了,要定义一个引用类型
MyInt result = new MyInt();
new Myint()将会出现在托管堆中,而result被定义在堆栈中,其内容是指向 new MyInt()的地址,如下如所示:
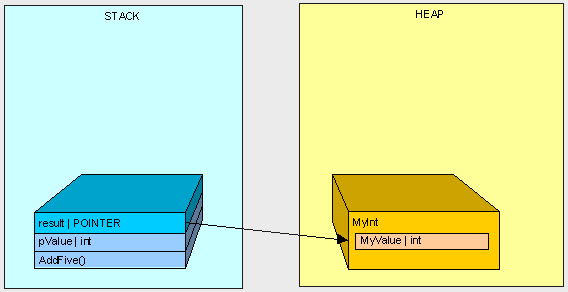
AddFive方法执行完毕后 stack将被清理,而heap将会被保留一段时间,这一段时间示情况而定,如果没有任何引用指向MyInt 垃圾管理器将会在合适的时候(不确定的时间)处理它

这样就能很好的回答问题一了:
值类型嵌套引用类型 : 和代码段二的理解方式一致,值类型将会被分配在stack上,二其内部的引用将会在heap上被声明.
引用类型嵌套值类型:如上图的邮编堆,都会被声明在heap上
欢迎加群讨论技术,1群:677373950(满了,可以加,但通过不了),2群:656732739。有需要软件开发,或者学习软件技术的朋友可以和我联系~(Q:815170684)